12月
13
基于Win32项目创建MFC工程
虽然通过visualstudio的app wizard可以创建一个MFC应用程序,但要理解MFC的运行过程,建议还是从0开始一步步搭建起MFC程序结构,熟练后反过来去看wizard创建的MFC代码,就很容易理解。
- 创建项目选择
Win32项目
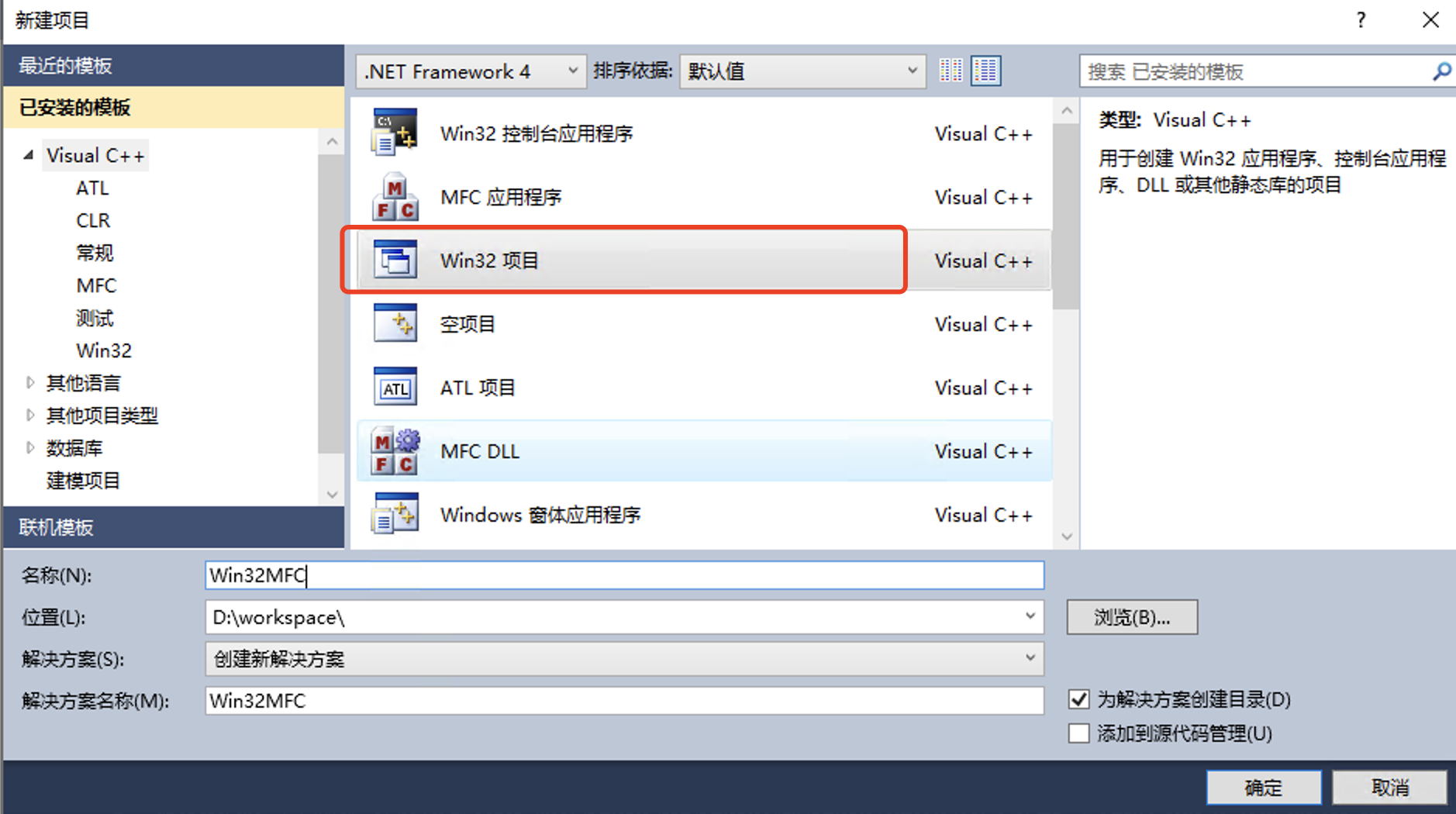
虽然通过visualstudio的app wizard可以创建一个MFC应用程序,但要理解MFC的运行过程,建议还是从0开始一步步搭建起MFC程序结构,熟练后反过来去看wizard创建的MFC代码,就很容易理解。
Win32项目在本地下载以下四个安装包
将安装包上传至服务器
Read the rest of this entry
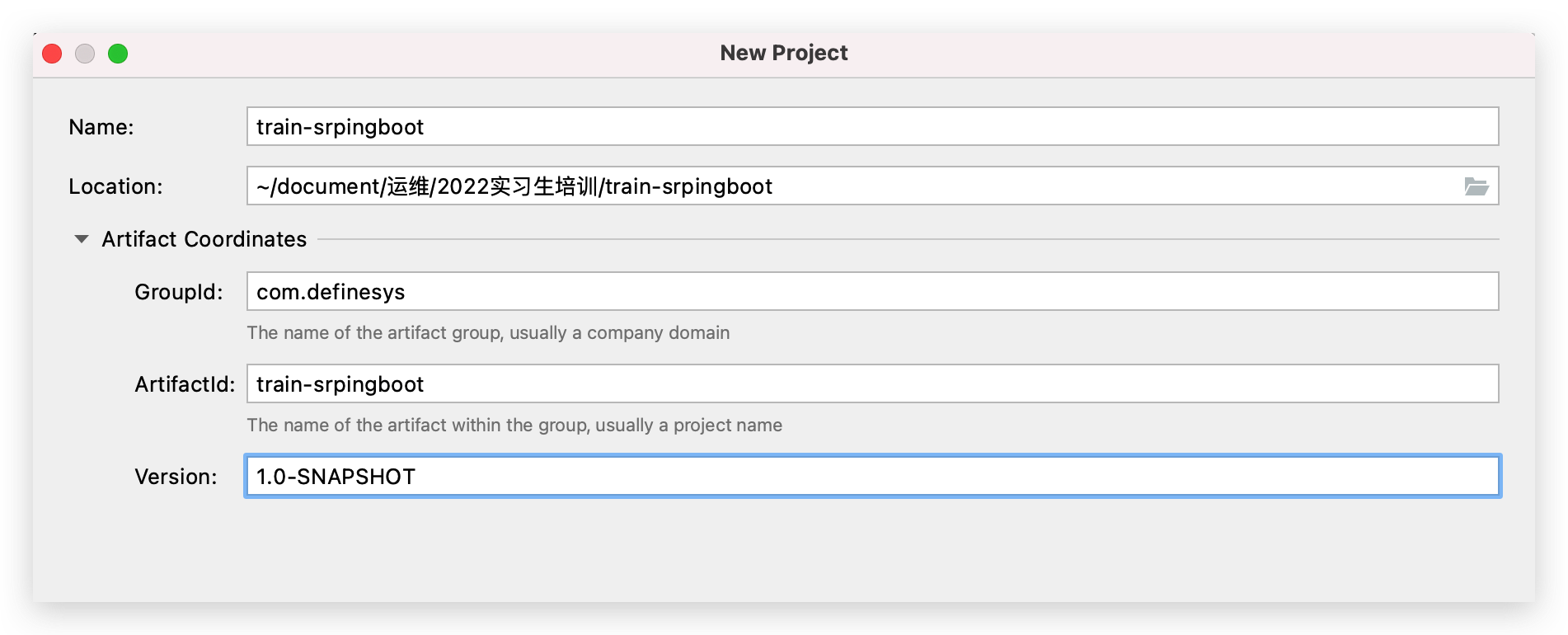
GroupId:一般是公司域名 Arttifactid:项目名称 Version:版本号,SNAPSHOT表示目前是快照版本,快照版本提交中央仓库不需要审核,并且能够实时更新
Read the rest of this entry
目前越来越多的应用都是运行在kubernetes环境中,kubernetes可以为应用提供更加稳定的运行环境,但也导致了调试不方便问题,通常线上问题我们会通过arthas工具进行调试,在落地实施我们发现
如果arthas能够通过web连接应用将极大方便程序的调试,因此arthas也提供了Arthas Tunnel进行远程调试。
Read the rest of this entry
apple所有的开发都要求在mac环境下进行开发,无法在windows和linux环境下进行,因此首先你必须得有一台mac,开发用途建议选择macbook pro型号,XCode是apple应用开发平台,可以从App Store上直接下载安装。本系列教程所有代码都基于以下环境编写运行
Read the rest of this entry
客户生产系统有张表存储流程bpmn文件,由于某些原因,更新程序找不到,因此只能连接数据库直接更新字段,数据库是oracle数据库,字段类型是blob。
一开始通过PL/SQL Developer工具进行编辑,bpmn文件使用UTF-8编码,但是在工具中查看是乱码,因此不能直接编辑
Read the rest of this entry
➜ cnpm install -g @vue/vue-cli ➜ vue create vue2project Vue CLI v5.0.4 ? Please pick a preset: (Use arrow keys) ❯ Default ([Vue 3] babel, eslint) Default ([Vue 2] babel, eslint) Manually select features
在创建项目的时候选择Vue2即可
如果不希望使用最新版的cli可以安装只支持vue2的clie
cnpm install -g @vue/cli@3.10.0
Read the rest of this entry
onlyoffice提供文档构建服务(document server),通过文档构建服务可以对文档进行二次修改,也可以动态创建文档,文档构建服务支持,文档构建服务支持以下编程语言进行构建
并且在onlyoffice的插件开发中,也可以使用node.js的api,这个在插件篇也会提到
Read the rest of this entry
onlyoffice提供文档转换服务,基本涵盖了几乎所有常见文档之间的转换,可以看下word文档能转换成的文档格式就知道其强大
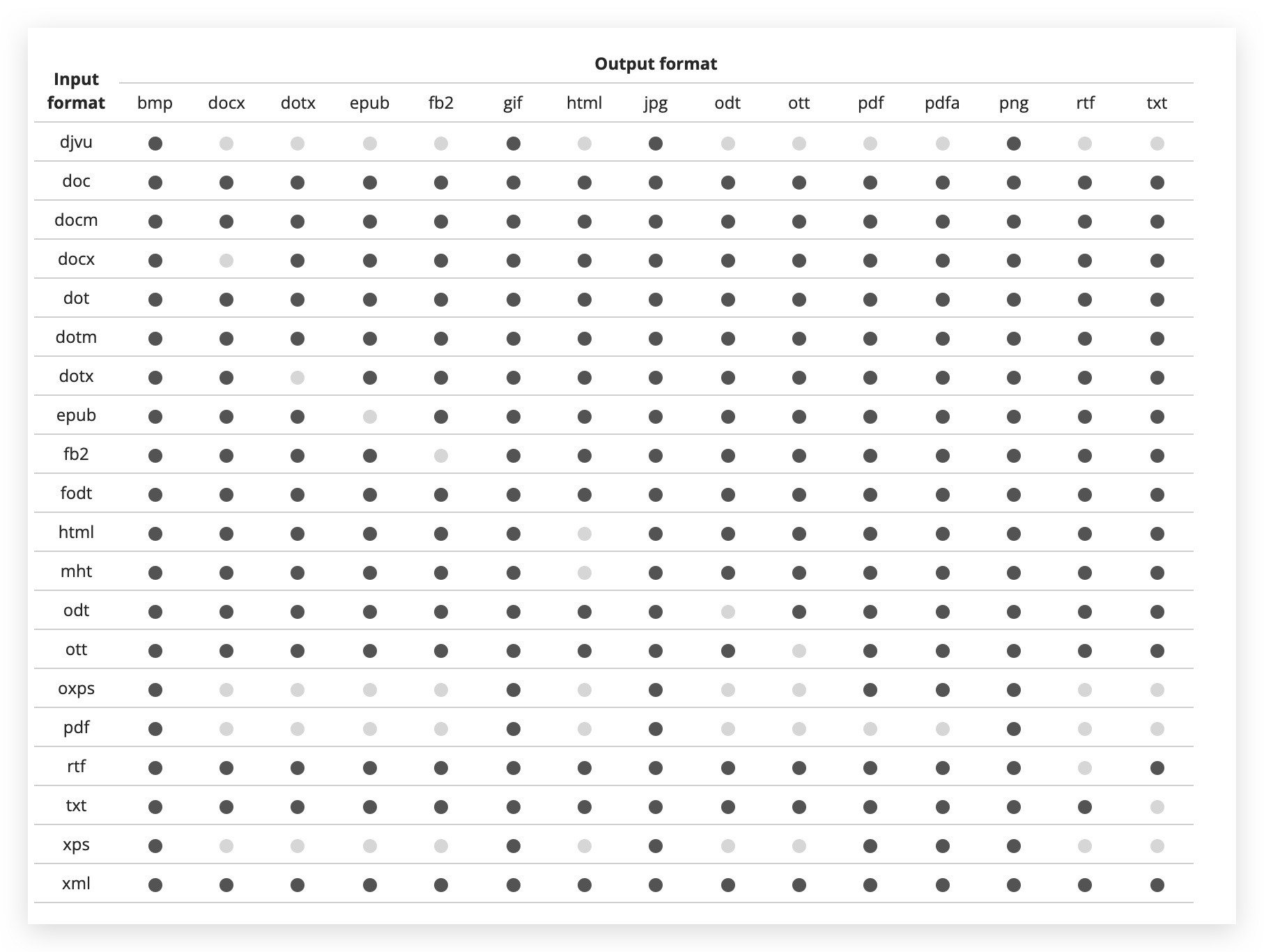
文档转换是通过接口来完成的,接口地址是https://documentserver/ConvertService.ashx,documentserver是documentserver的地址。这里列举几个常见的转换例子
Read the rest of this entry
onlyoffice对文件保存处理流程如下
首先,和上一篇一样,本地创建html文件
Read the rest of this entry
 闽ICP备19023998号-1
闽ICP备19023998号-1